Computer Organization
Instruction Set Architecture¶
Introduction to ISA¶
指令集系统,是微体系结构的需求
Operation Code (opcode) + (Source Operand Reference, Result Operand Reference) operands, Next Instructions Reference (实现 jump 功能)
操作数存储的位置:内存、寄存器、I/O 设备(可以像操作文件一样操作 I/O 设备),立即数(指令本身)
指令的格式:short, long, variable;操作数的数量:0/½/3;寄存器数量;对齐方式/最小单位 - byte/word;直接寻址、间接寻址、下标寻址
软件只能通过 ISA 和硬件交互
一种 ISA 可能对应多种 CPU 架构 (\mu-architecture)
About ISA design¶
操作数
3操作数 / 2操作数 / 1操作数(借助累加器)/ 0操作数(把栈顶两个数加起来再塞回去)
0操作数的实际是按照逆波兰表达式(Reversed Polish Notation)运算的
操作数的增加会使得程序内指令数变少,但是取(fetch)指令、执行(execution)指令时速度变慢
寻址
一个操作数实际的地址 The actual location of an operand is its effective address
寻址(寻址是指操作数如何引用我们感兴趣的数据)模式 Addressing Modes
- Immediate 立即数(如果这个数太大了,超出指令规定的立即数长度,就会出问题)
- Direct 直接寻址(把那个地址存的数拿来参与运算,遇到地址太长怎么办?用相对地址)
- Indirect 间接寻址(把地址存的数作为地址,再找这个地址对应的数拿来参与运算;缺陷:需要二次寻址浪费时间;优势:第二个地址对应的数是可以在运行过程中改动的,所以可以循环)
- Register Direct/Indirect 寄存器直接寻址(直接把寄存器的值作为运算数)
- Relative, Indexed and Based 寄存器间接寻址(把寄存器的值作为地址,参与运算)
- Relative addressing 相对寻址(用 PC 中的数据作为 offset,加到运算数中,再作为地址寻找对应的数)
- Indexed addressing 变址寻址 用寄存器再加上一个寄存器 作为地址 寻找对应的数
- Based addressing 基址寻址 用寄存器再加上一个数 作为地址 寻找对应的数
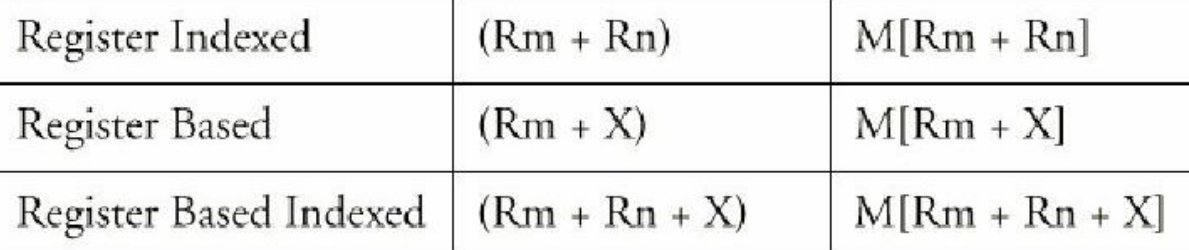
操作数和编码的种类
Types of Operations
▪ Arithmetic and Logic ▪ Shift ▪ Data Transfer, E.g., MOV/LOAD/STORE ▪ String ▪ Control, BRANCH/JMP/CALL/RET/… ▪ System, HALT/INTERRUPT ON/INTERRUPT OFF/SWITCH… ▪ Input/Output
Types of Encodings
Variable 变长、Fixed 定长、Hybrid(几个定长组合起来)
变长的可以缩短代码长度,定长的更加性能友好
分类
CISC Complex Instruction Set Computers
写的一条指令可以干好多事情,对译码、编译的效率要求很高
如果想新加一个指令,需要考虑很多
RISC Reduced Instruction Set Computer
指定了一些基础元素
Load-store architecture
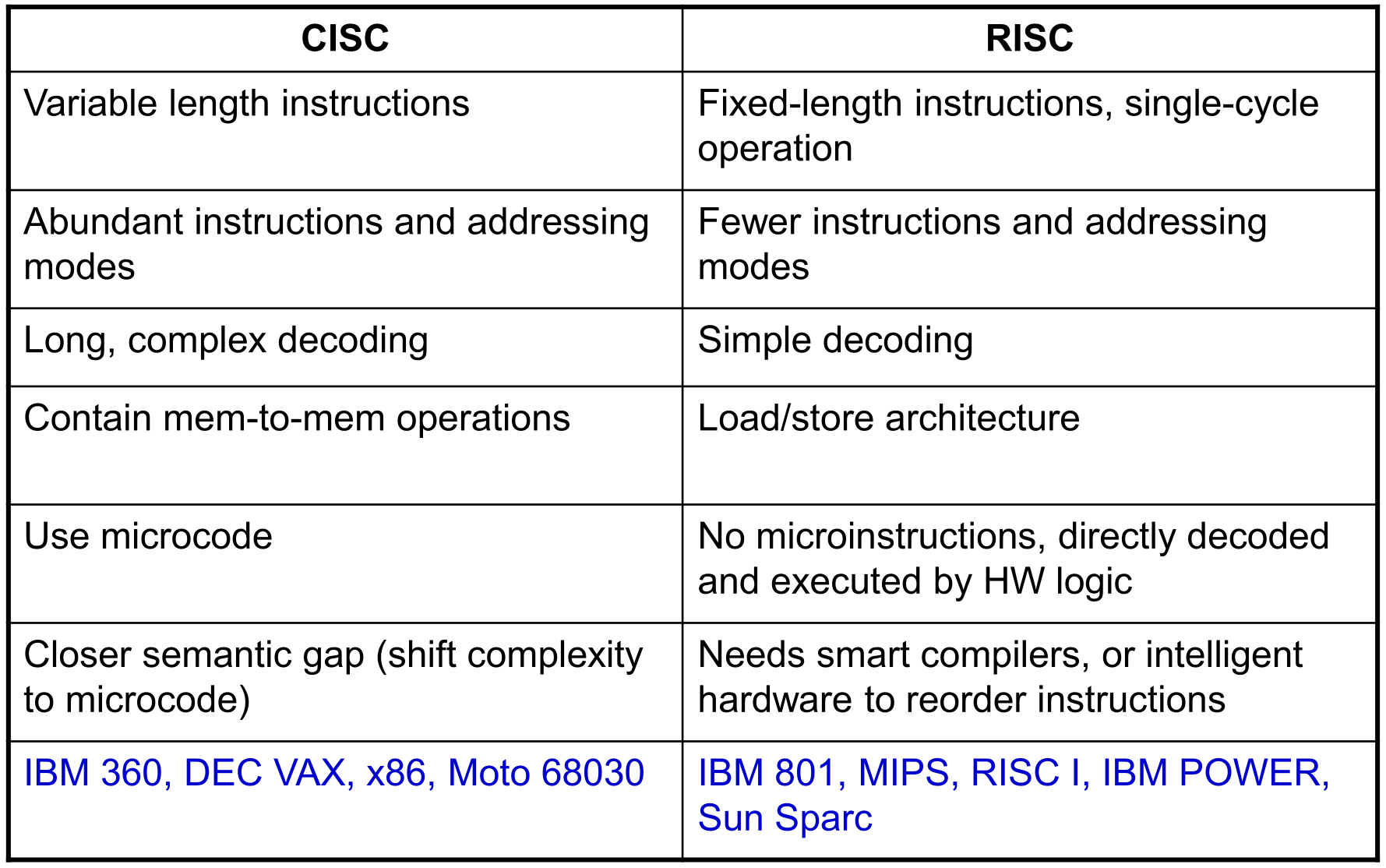
在慢慢融合
Classification of ISAs
Accumulator 1-address
Stack 0-address 指令比较短,虚拟机本身的实现比较简单,没有利用寄存器效率低,难于并行
Memory-Memory 2-address, 3-address
Register-Memory 2-address
Register-Register (Load/Store) 3-address
RISC-V ISA¶
optional customer extensions 额外支持一些指令,使得解码更快
User-level ISA, Compressed-level ISA (e.g. 16bits), Privileged-level ISA (引导类的)
命名:RV + word-width + extensions, e.g. RA32I,添加整型相关指令(ALU, 分支,Load/Store);乘除法 M
RV64 的指令长度是 64 位的,RV32 的指令长度是 32 位的
Register
PC Program Counter 存储要执行的指令的位置
FSR FP status register 保存了 FP rounding mode, exception reporting 溢出
32个 32/64 位寄存器:每个寄存器都还有各自特定的含义
x0 是只读的,永远是 0,可以用 add x0, x0, x0 表达 nop 操作
x1 中自动保存函数返回值
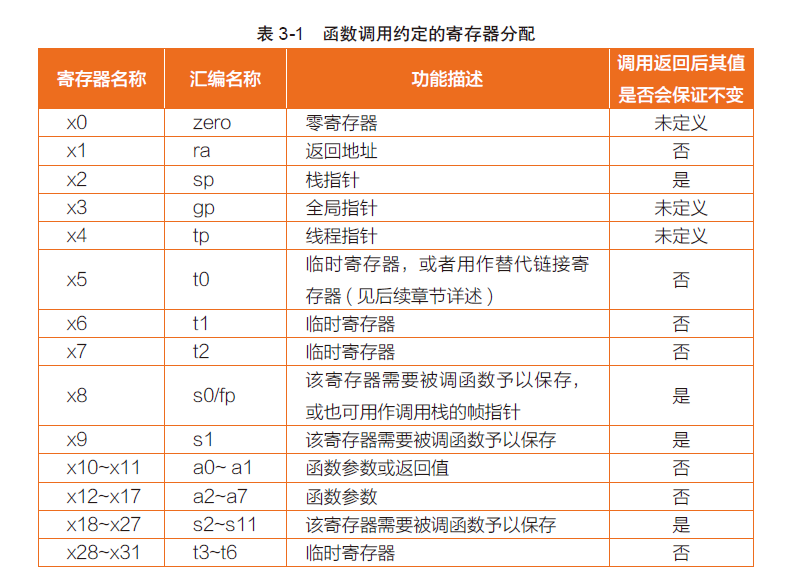
Instructions
j 开头的无条件跳转,b 开头的有条件跳转
blt 按照符号数进行减法,bltu 按照非符号数减法
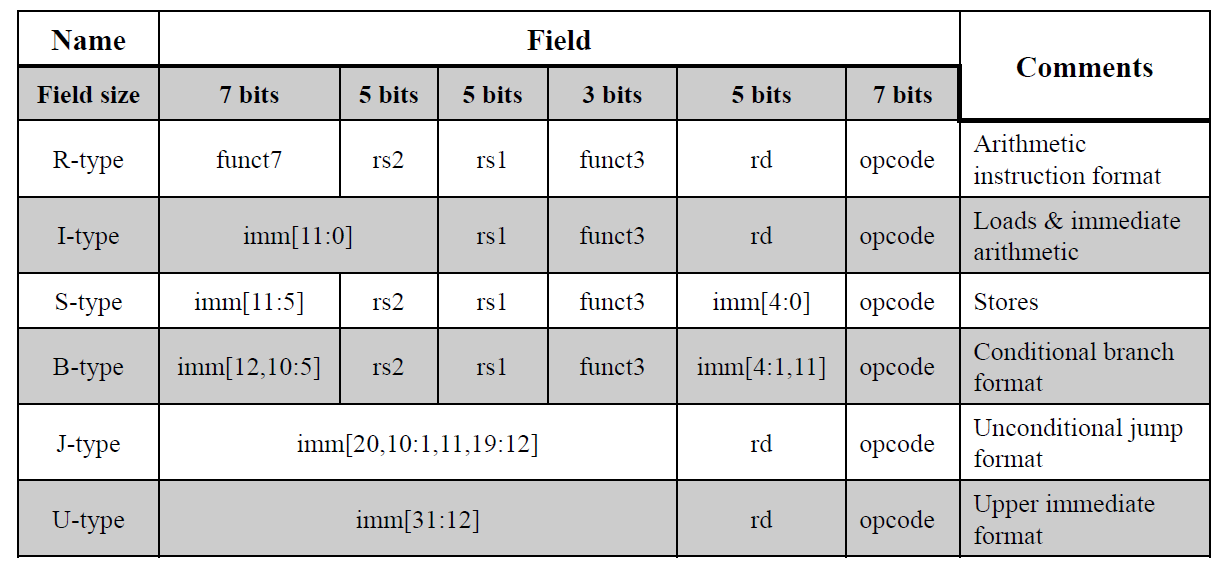
不同类型的指令编码方式是不一样的,会在 opcode 中明确 Type,Type 大类中的具体类型会在 funct3 中明确。
R 型和 I 型指令中,ALU 相关的,opcode 都相同,具体的计算是哪一个只用 funct3 编码
I 型支持 12 位立即数
Load (I-type): rd = Mem(rs1 + imm),Load 是 I 型!
LW x13,4(x12): 在x12寄存器中的数加上4的偏移量对应地址中,读出四个字节,存到x13寄存器中。
lh 是读 2 bytes 然后符号扩展,lhu 是读 1 byte 然后零扩展。lb, lbu 1 byte
Store (S-type): Mem(rs1 + imm) = rs2 的低x位
SW rs2,offset(rs1)
U-type 高位立即数类型 课程中不会太多涉及
Modes
Machine Mode, Supervisor Mode, User/Application Mode 层级越来越高,许多功能也会被屏蔽
Machine Mode 是机器自动做的,
RISC V Assembly Language¶
函数调用
Caller, Callee
Caller: Passes arguments to callee, Jumps to callee
Callee: Performs the function, Returns result to caller, Returns to point of call
函数调用 6 阶段:
Calling 要把参数放在 Callee 可以访问的地方
把 PC 指向 Callee 的位置
获取数据
执行函数
把返回值放在 Caller 可以访问的地方、把寄存器还原、把存储资源还原
把 PC 指回去
Prologue 函数的进入, Epilogue 函数的退出
如果参数很简单,那只需要 x10-x17 即可存储参数
如果参数复杂,那就需要对栈进行处理,e.g. sp 要指向正确的位置(sp 减掉需要占用的空间)


溢出:操作系统会把溢出之后被占用的数据挪到存储器的其他位置,这会造成数据泄露
C 语言代码运行过程
Compile - Assemble - Link - Load
Linker: Jump 到哪里
Loader: 把硬盘里的可执行文件 Load 到 Memory,并且确定程序开始运行的入口
Compiler
Preprocessor (*.c → *.i): Expands all macro definitions and include statements (and anything else starting with a #) and passes the result to the actual compiler.
Compiler (*. i → *.s)
汇编很难从代码本身读出具体含义
Assembler
不仅仅是翻译成机器码,还会把一些伪代码 pseudoinstructions 给变成标准代码
汇编语言中没有地址,使用 Symbol 来进行代码段/数据的标注;但是 .o 文件中就有了地址,
Linker
编译中,耗时太长;所以可以把一些需要调用的库提前编译成 .o 之后,只 Link 到一起即可。
Static vs. Dynamic Linking
Static: Link 完之后再执行即可,但是 Dynamic 的就只在运行的时候再去找、去 Link
The Processor: Basic Principles¶
Non programmable System: Specific System
Programmable System : General system
Finite state machine machine FSM, Program state machine PSM
假象出的图灵机
-
Tape: 纸带
-
Head: 只能做向左移、向右移、读/写
-
Table: 下一操作的规则
-
Register:current state
每个命令都是7元组,Program 都是5元组
问题:存储介质肯定是有限的、速度
图灵机中,不会保存中间状态;但是在实际实现的机器中,可以向 Register 保存这些中间状态。
通过 CPU 实现了一个更加强大的 Head。
寄存器可以通过一个 WE (Write and Enable) 来控制是否可以写入
CPU 需要实现:
存储序列(无限长的纸带)、let 指令(HEAD中的基本操作)、控制流(控制准测的 TABLE)、寄存器(更多的状态存储和立即数)
这上面的 1, 2, 4 都是不需要逻辑规则的硬件,3 需要指令
指令的执行:从指令存储器中解析出指令地址,解码、读寄存器
指令的分类:内存读写 lw('i'), sw('s')、运算 add, sub, and, or('r')、控制流指令 b('b'), jal('j')
Performance 衡量标准: 响应时间、吞吐量等,现在还会增加一些能耗、成本之类的衡量标准
执行时间的定义:Elapsed Time (Total response time), CPU Time (without I/O time)
执行时间 = 1/CPU Execution Time
CPU Execution Time = CPU Clock Cycles * Clock Period = CPU Clock Cycles / Clock Frequency (Clock Rate) CPU 主频
Average cycles per instruction (CPI), CPI = CPU Clock Cycles / Instruction Count (IC),单条指令需要的 Clock Cycle 数
如果引入流水线或者并行,一般 CPI < 1,那就使用 IPC 来衡量,看每个 Clock Cycle 可以运行的指令数目。
The Processor: Design¶
Instruction execution in RISC V¶
指令的规整性
操作数:2类 - 寄存器、立即数
要注意区分指令中的 rs1, rs2。
sub x5, x6, x7 中,x6 是 rs1,x7 是 rs2。
ld x5, 40(x6) 中,x5 是 rd。
sd x5, 40(x6) 中,x5 是 rs2,x6 是 rs1。
beq rs1,rs2,offset。
数据通路 Datapath¶
指令执行过程:
-
使用
PC中保存的地址,到指令存储器中读取指令后,改变PC的值。 -
解码转为机器码,读操作数 operand (指令中用到的寄存器等)
- 执行/内存访问/写寄存器/改变PC,取决于指令类型:Executive Control, Memory Access, Write results to register, Modify PC
第一步为 Fetch Instruction:需要用到指令存储器的读取、PC 这个寄存器、加法器
第二步为 Instruction Decoding & Read Operand:翻译为机器码,读取 Register Operands
译码时,一部分是 control signal 的设计,一部分是要访问实际地址
寄存器组的输入输出中:每个寄存器的地址接口是 5 位(\log_2 32)的,输入输出的数据(从寄存器中读到的/写入寄存器中的数据)是 32 位的。
数据通路图:图中的 64 都应该是 32。
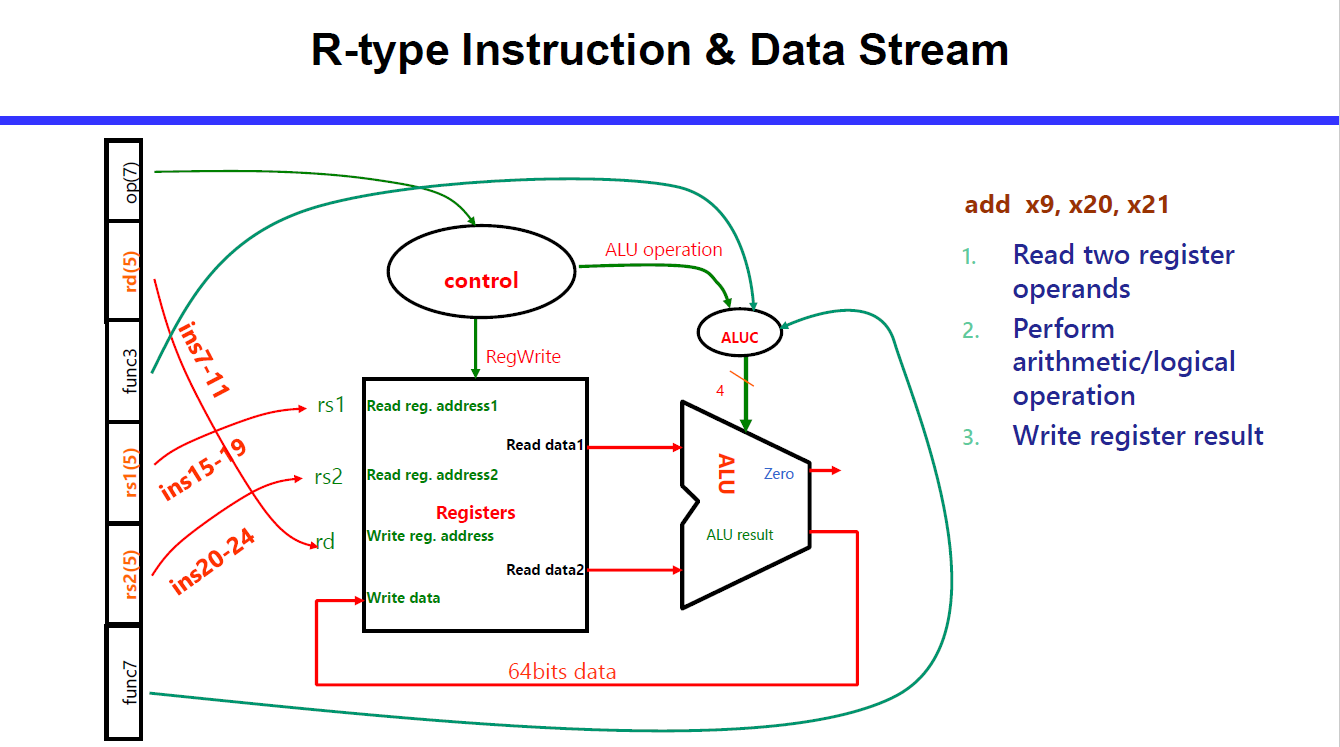
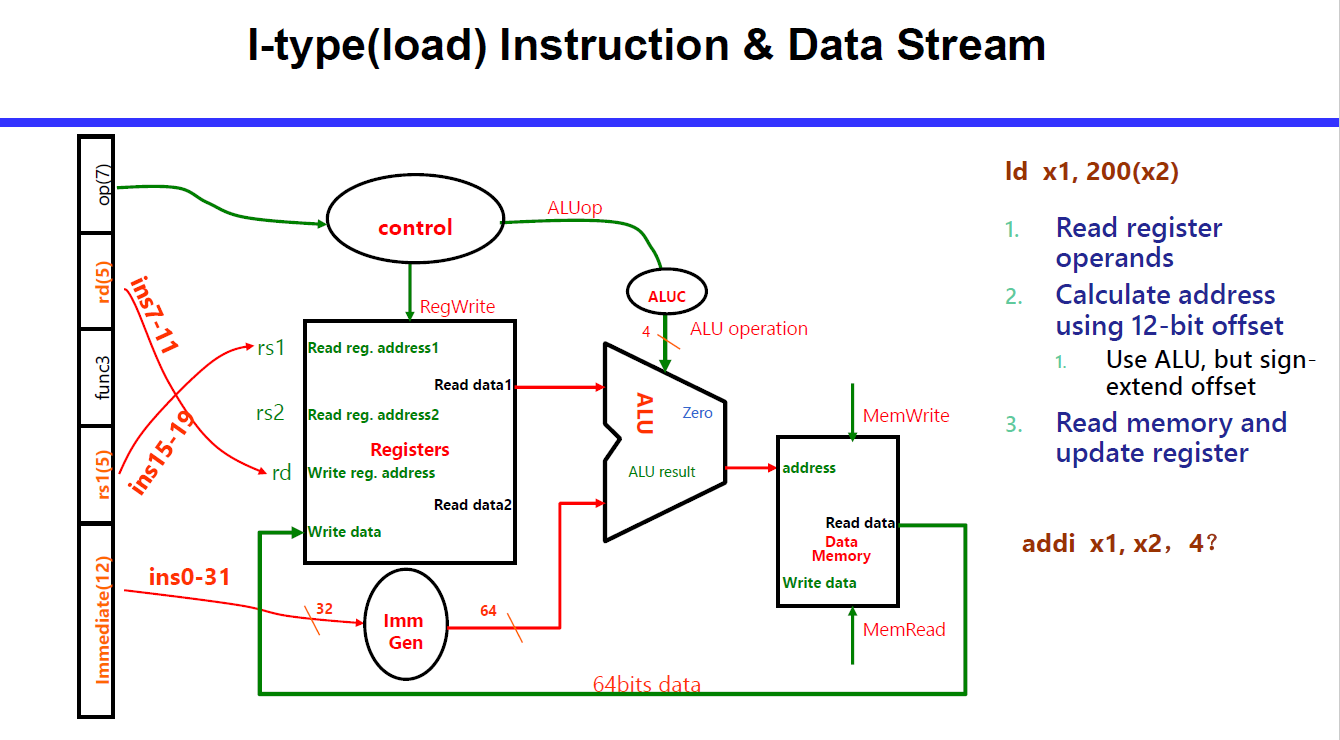
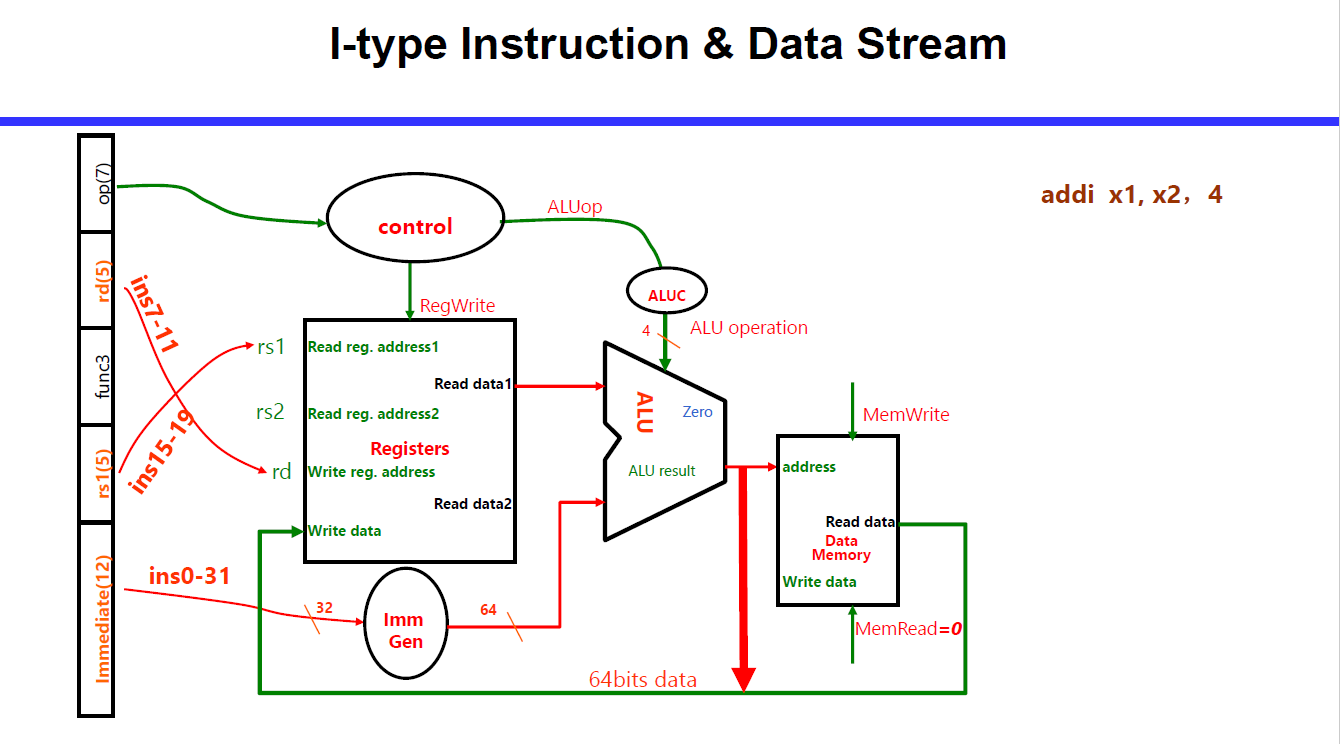
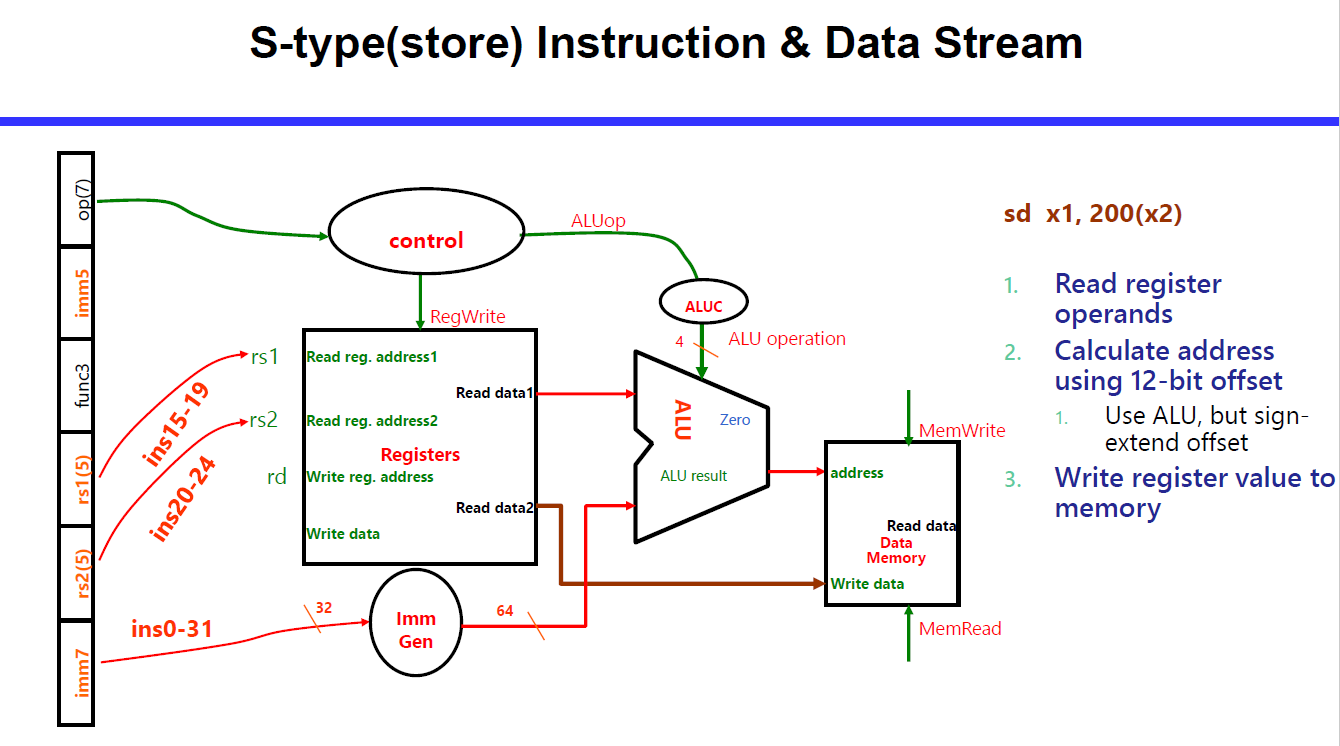
R, I, S 相对类似
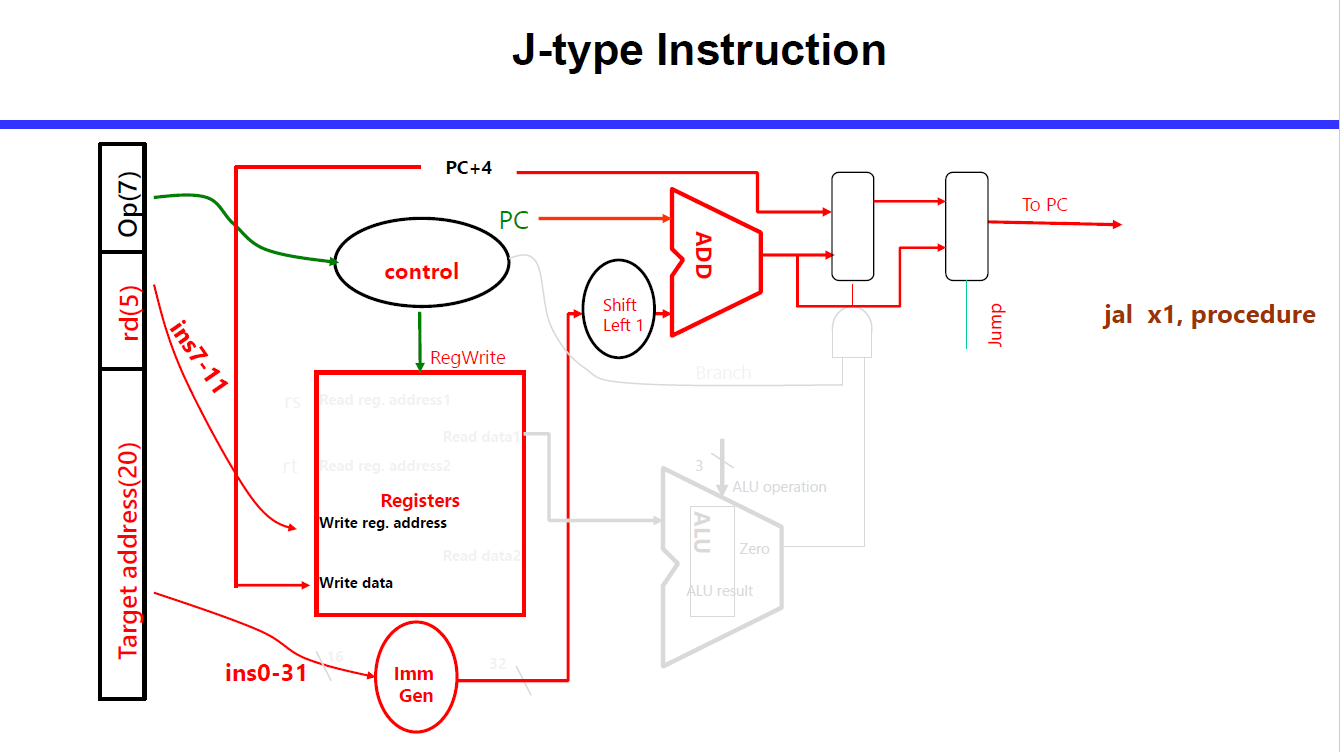
B, J 涉及对 PC 的修改。
为什么需要 左移1位?因为编码中没有第0位,是从第1位开始编码的,默认就要乘2。
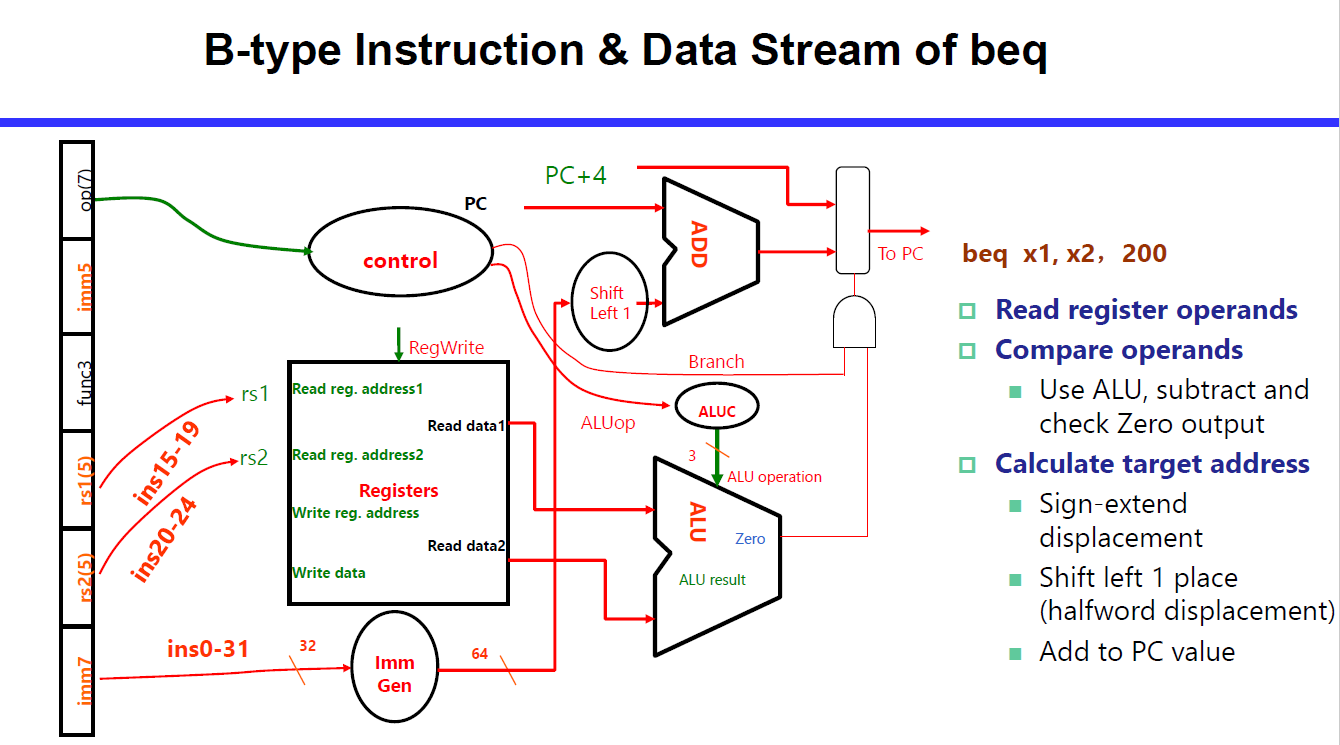
B 中需要 ALU 中输出的 zero flag,而不是输出;计算 PC+offset 时需要使用额外的加法器。然后再把 PC+4 和 PC+offset 用 branch AND zf 来进行多路选择,赋值给 PC。
为了方便把 J 型指令的数据通路和 B 型合并到一起,所以认定 ALU 是数据流的操作,而额外的 Adder 专门负责处理 PC 的加法。
通过多路选择器来实现 Share,两个输入一个输出的时候,需要通过数据信号来确定数据究竟选择哪个。
控制32个寄存器,需要32位多路选择器。
控制器 Controller¶
4 bits, ALUSrc, MemtoReg, Branch, Jump,多路选择器的控制部件;
2 bits, ALU operation,ALU 的控制;
3 bits, RegWrite, MemRead, MemRrite,读写操作,从操作数中得到。
2 阶段控制器 - Main Decoder, ALU Decoder
Main Decoder 只需要接收 opcode,不需要其他的
控制信号确定:根据类似真值表的方式,写出关于 OPCode 的逻辑表达式。
ALU Decoder 接收 Main Decoder 传过来的 2 bits ALU op,然后再读 func3, func7,最后输出 4 bits 的 ALU Control 传给 ALU。
时钟周期:取址、译码、执行控制、访存、写回
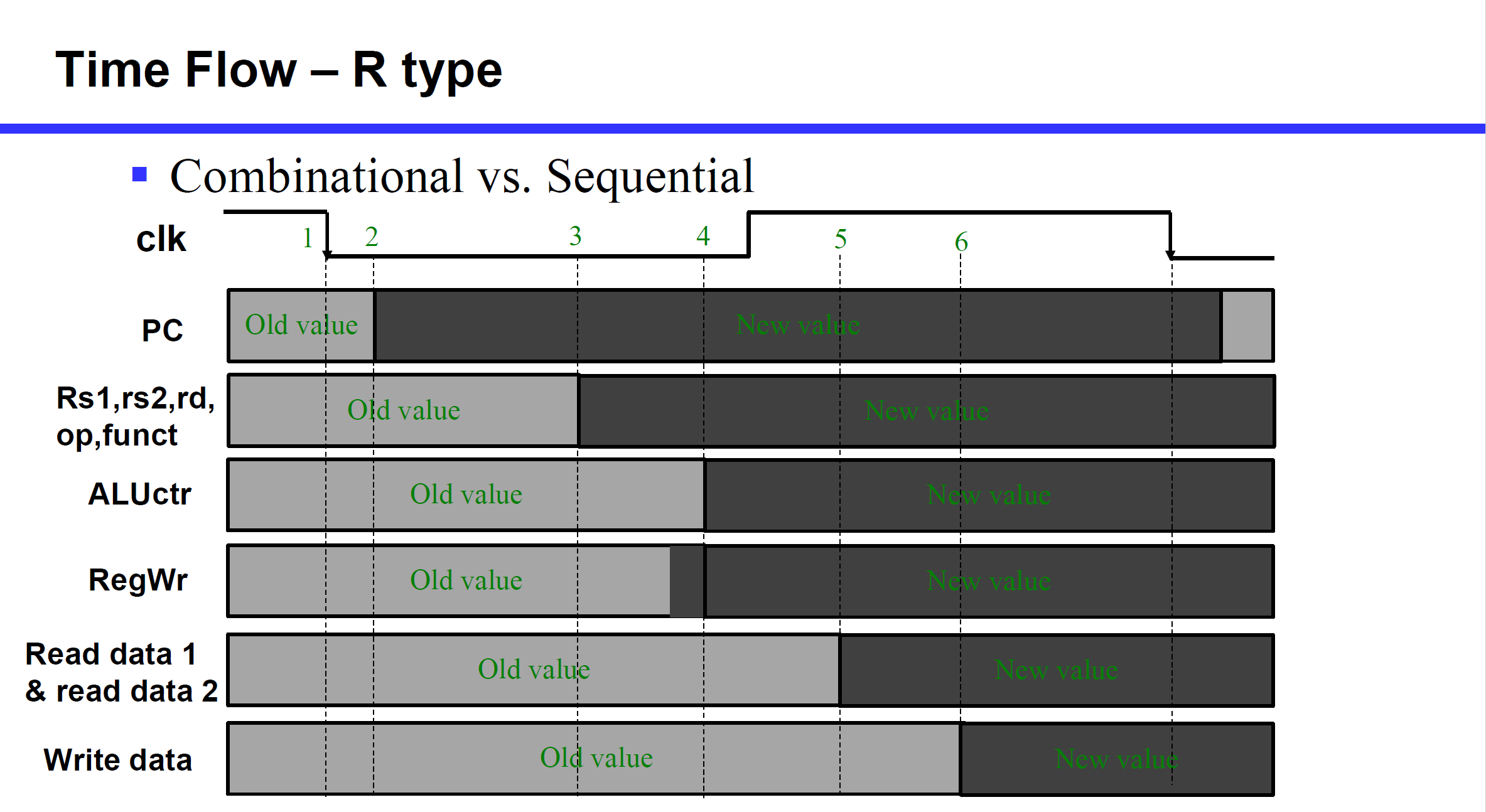
R型指令没有访存。
最后一步 write data 只是把东西计算好,并没有写回寄存器组,写回是在下一个时钟周期进行的。
PC 的修改不会单独占用某一个时间,是并行的。
R Type:
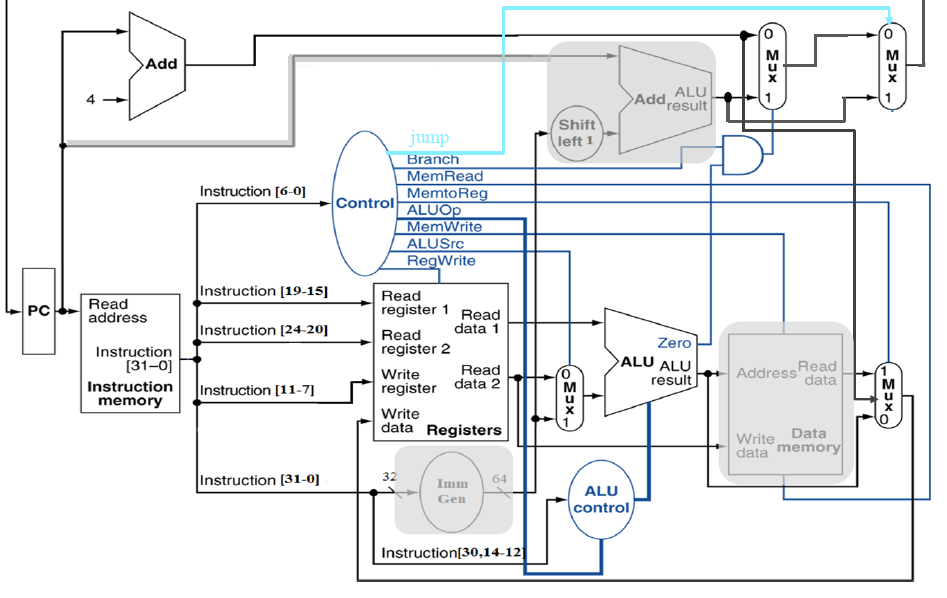
Multi-Cycle CPU Design¶
优化方法:减少指令数(CISC)、减少每条指令所需时间(RISC)、增加时钟频率
CPU中:数据通路、控制器、缓存
多周期:
仍然是:取址 IF、译码 ID、执行控制 EX、访存 MEM、写回 WB
大幅度减少一个时钟周期的长度,可以用好多 Cycle 计算一条指令,可以复用一些昂贵的硬件。
不再需要等着那个时间最长的指令,不需要两个 Adder,两个 Memory(只能哈佛架构)。
可以使用冯诺依曼架构,使用寄存器进行指令和数据的分离。
使用寄存器保存周期之间的状态,是用来记录状态的组件。
IR instruction register
DR data register
数据通路
某一个周期中,涉及到的电路都是组合逻辑电路,只有在边界才是时序逻辑电路。
每个指令需要 3-5 个指令来执行,只有 Load 需要5个。
以下存疑:
取址:取到 PC,计算 PC + 4 等待下一个时钟周期写入 PC;经过多路选择器(决定是PC作为内存的下标还是用计算得到的数据作为内存的下标),从内存中取到当前地址的指令,然后放到 IR 里,等待下一个周期写入到 IR。
译码:写入 PC,把指令写入 IR;把 IR 中的数据译码到控制器、寄存器组对应输到 AB 等待下一个周期读取;对于 B 型指令,会利用立即数的组件把 Target 的计算也存起来,等待下一个周期把要跳转到的地址读取,这时由于 AB 还没有实际读到数据,所以并不知道条件是否成立。
执行:AB 中的数据计算后,存到 ALUout
访存:ALUout 写到内存
写回:把 IR 中的写回寄存器组
控制器
不同的时钟周期内,对于同一个指令,控制信号是不同的。控制器变成了时序逻辑部件(是时钟直接导致他变)。
硬连线控制器 Hardwired Controller - RISC,基于有限状态机 FSM
微指令控制器 Micro-program Controller - CISC
Hardwired Controller FSM: Reset -> IF -> ID 之后分叉。
具体实现中,硬连线控制器中也是含有状态寄存器的,要把输出作为下一个时钟周期的输入;内部是组合电路,但是状态寄存器的输入中有时钟,所以是随时钟变化的。
硬连线的好处:内部实现都是组合逻辑,没有延迟;但是如果又增加新的指令,那会导致过于复杂。
微指令的坏处:需要更长的执行时间
计算 CPU Time: Critical Path - 涉及到电路最多的/涉及到存储器的